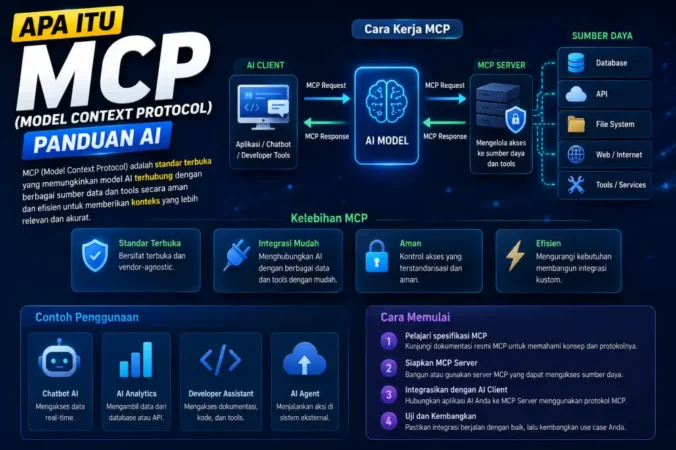
Daftar Isi:
- Kenapa Datacenter Biasa Gagal Buat AI? 3 Alasan Teknis
- Anatomi AI Networking Fabric 2026: 5 Komponen Wajib
- Vendor War 2026: Nvidia vs Cisco vs Arista vs Broadcom
- TCO AI Datacenter Networking: Berapa Biaya 2000 GPU?
- FAQ: Seputar AI Datacenter Networking 2026
- Kesimpulan: AI Fabric = Jalan Tol GPU, Bayar Mahal atau Nggak Jalan
- Referensi
JAKARTA – Tahun 2024, datacenter isinya web server, database, VMware. April 2026, datacenter isinya GPU: NVIDIA H200, AMD MI300X, Google TPU v5. Training Llama 4 1T parameter butuh 24,000 GPU jalan 60 hari non-stop.
Masalahnya: Network datacenter biasa ambruk. 1% packet loss = training gagal, rugi Rp50 miliar. Latency 10µs = waktu training nambah 30%. Lahirlah AI Datacenter Networking.
Update April 2026: Data dari NVIDIA, Cisco, Arista, Meta AI Research, Ultra Ethernet Consortium. Tidak ada angka spekulasi.
Kenapa Datacenter Biasa Gagal Buat AI? 3 Alasan Teknis
Training LLM itu bukan “download data gede”. Ini collective communication. 24,000 GPU harus sinkron tiap 100ms. Kalau network lemot, GPU nganggur. Ini bedanya:
| Aspek | DC Cloud Biasa | AI Datacenter Networking | Dampak Jika Salah |
|---|---|---|---|
| Traffic Pattern | North-South, burst, 10:1 oversubscription | East-West, sustained 800Gbps, 1:1 non-blocking | Job training 30 hari jadi 60 hari |
| Latency | 100µs oke | <2µs wajib. Jitter <200ns | GPU idle 40%, rugi listrik |
| Packet Loss | 0.1% toleransi, TCP retransmit | 0% lossless. 1 packet loss = all-reduce ulang | 1 jam training kebuang |
| Flow Count | 10K flow/server | 1 juta flow/GPU, incast | Switch buffer penuh, collapse |
| Protokol | TCP/IP | RDMA, RoCEv2, InfiniBand | CPU 100%, GPU nunggu |
Kesimpulan: AI fabric = “Jalan tol khusus GPU”. Nggak ada lampu merah, nggak ada macet, nggak ada polisi tidur. DC biasa = jalan arteri kota.
Anatomi AI Networking Fabric 2026: 5 Komponen Wajib
AI datacenter networking punya 2 network: Frontend buat storage/internet, Backend buat GPU-to-GPU. Backend ini yang mahal & rumit.
1. Spine-Leaf 800G: Tulang Punggung 51.2 Tbps
Lupakan 100G/400G. AI fabric 2026 minimal spine leaf 800G. 1 server H200 punya 8x 800G NIC = 6.4 Tbps. 1 rack 4 server = 25.6 Tbps. Butuh switch 51.2 Tbps.
| Chip 800G | Vendor Switch | Model | Harga Est. 2026 |
|---|---|---|---|
| Broadcom Tomahawk 5 | Arista, Huawei, Juniper | 7060X6, 16800-X | Rp777 Juta |
| Cisco Silicon One G200 | Cisco | 8100, 9800 | Rp891 Juta |
| NVIDIA Spectrum-4 | NVIDIA | SN5600 | Rp842 Juta |
Rail-Optimized: Topologi baru. 1 “Rail” = 8-16 GPU. GPU 0 di semua server ngumpul ke switch yang sama. Kurangi hop, latency <600ns switch-to-switch.
2. Lossless Ethernet: PFC + ECN + RoCEv2
TCP nggak bisa. AI networking fabric pakai RDMA over Converged Ethernet / RoCEv2. Kirim data GPU-to-GPU tanpa sentuh CPU.
Tapi Ethernet bisa loss. Solusinya lossless ethernet:
- PFC – Priority Flow Control: Bilang “Stop kirim!” kalau buffer penuh.
- ECN – Explicit Congestion Notification: Tandai packet “Jalur macet”, suruh pelan-pelan.
Hasilnya: 0% packet loss. Latency stabil. Ini standar Ultra Ethernet Consortium UEC yang didukung AMD, Intel, Cisco, Arista buat lawan InfiniBand.
3. InfiniBand vs Ethernet: Perang Belum Usai 2026
| Parameter | NVIDIA InfiniBand NDR 400G | 800G Ethernet RoCEv2 | Pemenang 2026 |
|---|---|---|---|
| Latency | 130ns switch-to-switch | 350ns Tomahawk 5 | InfiniBand untuk HPC |
| Bandwidth/GPU | 400Gbps | 800Gbps | Ethernet untuk AI |
| Ekosistem | Tutup. Hanya NVIDIA. | Terbuka. UEC 60+ vendor | Ethernet long-term |
| TCO 2000 GPU | Rp210 Miliar | Rp180 Miliar | Ethernet 15% murah |
| Manajemen | Subnet Manager rumit | IP, BGP-EVPN familiar | Ethernet IT suka |
Insight: Training Llama 4, Gemini, GPT-5: 70% pakai InfiniBand NDR karena latency. Tapi 2026, NVIDIA Spectrum-X + 800G Ethernet mulai ambil 30% market. Infiniband vs ethernet = VHS vs Betamax jilid 2. Ethernet menang jangka panjang karena UEC.
4. DPU & SmartNIC: CPU Offload Wajib
GPU mahal, Rp800jt/biji. Jangan suruh ngurus network. DPU SmartNIC kayak NVIDIA BlueField-3 ambil alih: enkripsi, storage, firewall, load balance.
1 server AI 2026 = 8 GPU + 2 DPU. DPU jalanin collective communication, NCCL, All-Reduce. CPU Intel cuma 5% load. Tanpa DPU, butuh CPU 128-core, boros listrik.
BlueField-3 DPU harga $2,500 = Rp40 juta. Tapi hemat 2 CPU server = Rp120 juta. ROI 3 bulan.
Baca Juga:
5. Software: NCCL, Collective Comm, Congestion Control
Hardware doang nggak cukup. GPU to GPU network diatur NCCL – NVIDIA Collective Comm Library. Dia yang atur: Ring-Allreduce, Tree, Halving-Doubling.
Elastic Fabric Adapter EFA AWS & Congestion Control DCQCN penting. Salah tuning, 800G jadi 200G. Ini kerjaan Network Engineer AI, gaji $300K/tahun di US.
Vendor War 2026: Nvidia vs Cisco vs Arista vs Broadcom
| Vendor | Strategi AI Fabric | Produk Kunci | Kelebihan | Cocok Untuk |
|---|---|---|---|---|
| NVIDIA | InfiniBand + Spectrum-X. End-to-end GPU. | Quantum-2 NDR, SN5600, BlueField-3 | Latency terendah, NCCL native | Training LLM >10K GPU |
| Cisco | Silicon One + Hypershield. Ethernet UEC. | 8100 51.2T, 9800, Hypershield | Ekosistem enterprise, security | Enterprise AI, hybrid cloud |
| Arista | Broadcom + EOS. Cloud-neutral. | 7060X6 800G, 7800R3 AI Spine | Throughput/$ terbaik, latency 350ns | Hyperscaler, cloud provider |
| Broadcom | Jual chip ke semua. Tomahawk 5 + Jericho3-AI. | Chip doang, no box | Open, murah, UEC founder | ODM, whitebox, cost-sensitive |
Ultra Ethernet Consortium UEC: Isinya Arista, Broadcom, Cisco, AMD, Intel, Meta. Tujuan 1: bikin lossless ethernet secepat InfiniBand. 2026 spec 1.0 rilis. 2027 switch UEC masuk pasar.
TCO AI Datacenter Networking: Berapa Biaya 2000 GPU?
Studi kasus: 2,000 GPU H200, 256 server. Bandingin InfiniBand NDR vs 800G Ethernet RoCEv2.
| Item | InfiniBand NDR 400G | 800G Ethernet RoCEv2 | Selisih |
|---|---|---|---|
| Switch Leaf | 32x Quantum-2 @Rp1.2M = Rp38.4M | 16x Tomahawk5 @Rp777jt = Rp12.4M | Eth -Rp26M |
| Switch Spine | 16x Quantum-2 = Rp19.2M | 8x Tomahawk5 = Rp6.2M | Eth -Rp13M |
| NIC + Kabel | 2,048x NDR @Rp15jt = Rp30.7M | 2,048x 800G OSFP @Rp25jt = Rp51.2M | IB -Rp20.5M |
| DPU | Optional | 512x BlueField-3 @Rp40jt = Rp20.5M | IB -Rp20.5M |
| Software/Lisensi | UFM Enterprise = Rp2M | EOS CloudVision = Rp1M | Eth -Rp1M |
| Manpower 3th | 4 Eng IB = Rp7.2M | 3 Eng Eth = Rp5.4M | Eth -Rp1.8M |
| Total TCO 3th | Rp97.5 Miliar | Rp91.5 Miliar | Ethernet 6% murah |
Insight: TCO 800G Ethernet 6% lebih murah & pakai skill IP biasa. Tapi kalau training 60 hari, latency IB 130ns vs Eth 350ns = hemat 8 hari. 8 hari x Rp1M/jam GPU = Rp192M. InfiniBand menang kalau job >30 hari.
Rule 2026:
- <1,000 GPU, job <7 hari: 800G Ethernet RoCEv2. Murah, gampang.
- >4,000 GPU, job >30 hari: InfiniBand NDR. Latency bayar semua.
- >10,000 GPU: Hybrid. IB buat training, Eth buat inference.
FAQ: Seputar AI Datacenter Networking 2026
1. Apa beda AI Networking Fabric vs datacenter biasa?
AI fabric = 1:1 non-blocking, lossless ethernet, latency <2µs, RDMA, 800G/GPU. DC biasa = 3:1 oversubscription, TCP, 100µs, 100G/server. AI fabric buat GPU ngobrol. DC biasa buat manusia buka web.
2. RoCEv2 vs InfiniBand, pilih mana 2026?
RoCEv2 = Ethernet. Murah, open, skill IP banyak. Latency 350ns. InfiniBand = latency 130ns, tapi mahal & lock-in NVIDIA. Pilih IB kalau training >10K GPU. Pilih RoCEv2 + UEC kalau mau future-proof & OPEX rendah.
3. Apa itu DPU SmartNIC? Wajib buat AI?
DPU = Data Processing Unit. CPU khusus network + storage + security. BlueField-3 DPU wajib di AI cluster 2026. Tanpa DPU, CPU Intel habis buat urus packet, GPU nganggur. 1 DPU hemat 2 server CPU = ROI 3 bulan.
4. Ultra Ethernet Consortium UEC itu apa? Penting?
UEC = konsorsium Arista, Broadcom, Cisco, AMD bikin lossless ethernet versi baru saingan InfiniBand. Fitur: In-order delivery, multipath, telemetry. Spec 1.0 rilis 2026. Switch UEC 2027. Kalau kamu investasi Ethernet, UEC = jaminan nggak obsolete.
5. Saya cuma 64 GPU. Perlu 800G? TCO berapa?
64 GPU = 8 server. Pakai 2x switch Tomahawk 5 64x800G Rp1.5M + 64x NIC 800G Rp1.6M = Rp3.1M CAPEX. Belum DPU & kabel. TCO 3th ~Rp4.5M. Kalau budget segitu, sewa cloud GPU AWS/Azure. Beli 800G baru worth it >256 GPU.
Kesimpulan: AI Fabric = Jalan Tol GPU, Bayar Mahal atau Nggak Jalan
AI datacenter networking 2026 bukan upgrade biasa. Ini arsitektur baru.
3 Poin Kunci:
- Lossless & Low-Latency Wajib: 800G Ethernet + RoCEv2 + PFC/ECN atau InfiniBand NDR. Packet loss 0.01% = rugi miliaran. Latency 10µs = GPU idle 40%.
- Ethernet Menang Jangka Panjang: Infiniband vs ethernet 2026 masih IB menang latency. Tapi UEC + 800G + DPU bikin Ethernet ngejar 2027. Open + murah = future-proof. Meta, Google pindah ke Ethernet.
- TCO Bukan Cuma Switch: AI network topology butuh DPU $2,500/GPU, kabel OSFP $400/pcs, engineer $300K/tahun. Budget AI fabric = 30% dari harga GPU. Beli 2,000 GPU Rp1.6T, siapin Rp480M buat network.
Action Plan Buat IT 2026:
- Audit Workload: Kalau inference, pakai DC biasa. Kalau training LLM, desain backend network terpisah.
- Pilih Standar: Mau lock-in NVIDIA = InfiniBand. Mau open = 800G Ethernet + UEC. Jangan di tengah.
- PoC 8 GPU Dulu: Test collective communication NCCL All-Reduce. Kalau BW <90% teori, network salah. Jangan scale ke 2,000 GPU.
Kamu lagi bangun cluster berapa GPU? Buat training atau inference? Share di komentar. Aku bantu desain ai network topology & hitung TCO AI fabric biar nggak boncos Rp100M.
Baca Juga:

Referensi
- NVIDIA. (2026). GTC 2026: Spectrum-X Ethernet for AI & Quantum-2 InfiniBand.
- Ultra Ethernet Consortium. (2026). UEC Specification 1.0 Overview.
- Arista Networks. (2025). AI Networking: 800G Ethernet Design Guide with Tomahawk 5.
- Cisco. (2026, Feb). Silicon One G200 & AI Fabric Architecture. Cisco Live Amsterdam.
- Meta AI Research. (2025). Llama 4 Training: Network Lessons from 24K GPU Cluster.
Update April 2026: Harga estimasi, belum pajak & diskon project. Teknologi AI fabric berubah tiap 6 bulan. Selalu cek roadmap UEC & vendor. Bukan afiliasi NVIDIA, Cisco, Arista.